Heuristics in Operating Systems: Concepts, Pitfalls, and a New Framework
1. Introduction
There lacks a study on kernel heuristics, even though heuristics is a big part of operating systems, as authors identify 68 heuristics in Linux memory management alone. The paper studies Linux kernel heuristics.
Three contributions done in the paper:
- Introduce a formal definition of heuristics, as there seems to be not one.
- With this definition, analyze 68 heuristics from 1000+ candidate code segments. And by analyzing them through commit messages and mailing list discussions, they uncover two major pitfalls for today’s kernel heuristics.
Pitfall 1: Heuristic anomalies
heuristic anomaly: the system performs worse with a given heuristic than either without it or with another heuristic
Pitfall 2: Lack of maintainability
Current heuristics are tightly intertwined with the kernel core logic, making them difficult to isolate, understand, or extend.
They isolate the heuristic logic from the rest of the kernel and modularize it behind a clean, well-defined interface. They reimplement 30 heuristics with the framework.
2. Heuristics Definition
Definition 1 (Problem, Solution, Procedure)
A well-defined problem is a tuple of $(X, S, C)$ , where $\mathcal{X}$ is the set of problem instances, $\mathcal{S}$ the space of solutions, and $C$ the correctness relation of $(X, S)$. For a problem instance x, a solution s is well-formed if $(x, s) ∈ C$.
Let $P$ be the set of procedures, where each procedure $p ∈ P$ is a mapping
[ p: X \to S ] such that for any instance $x ∈ X$, the output $p(x)$ is a well-formed solution, that is, $(x, p(x)) ∈ C$.
Definition 2 (Heuristic)
A heuristic is a transformation [ h: P \to P ] that maps one procedure to another. A heuristic procedure $h(p)$ is expected — though not guaranteed — to
- reduce the resource cost of computing $p(x)$, and/or
- improve the quality of the resulting solution
for a subset of instances in $X$ that appear often.
Scope of this paper
This paper examines heuristics in operating systems, with a focus on the Linux memory management subsystem. The study is restricted to well-defined problems—problems whose inputs, outputs, and correctness conditions are explicitly specified.
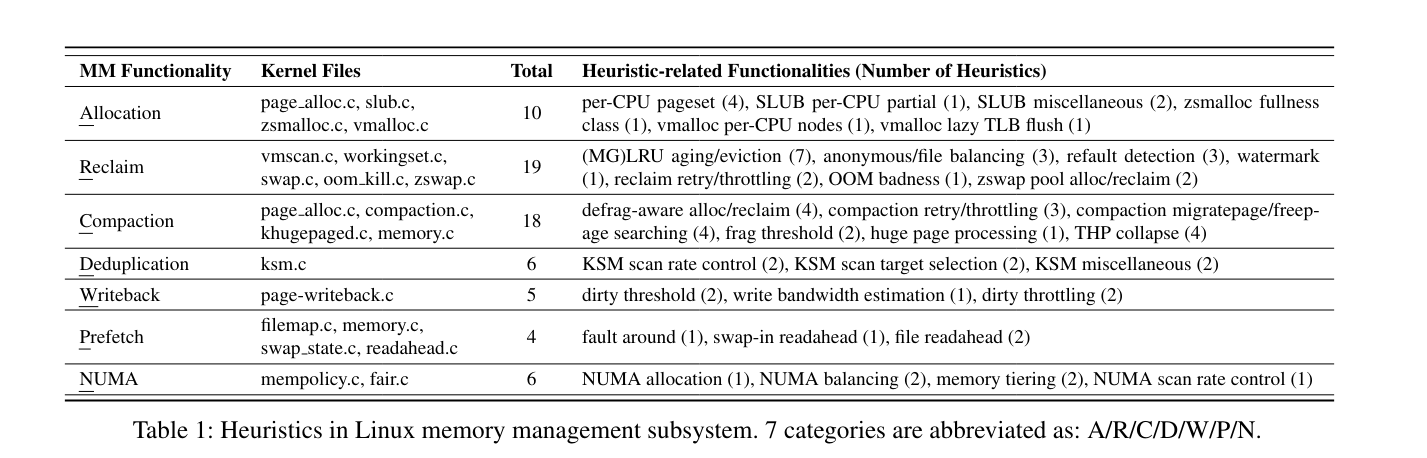
3. Heuristics in Linux Memory Management Subsystem
Identifying kernel heuristics
- Ask LLM to identify heuristic code segments from kernel functions. (Filters out 84% of kernel)
- Confirm and analyze each candidate code by reading the code and examining commit messages via
git blame. (Filters out 96% of candidates, leaving 68 real heuristics) - Review the corresponding mailing-list discussions to understand the effectiveness of each heuristics and the original problem that motivated the heuristics.
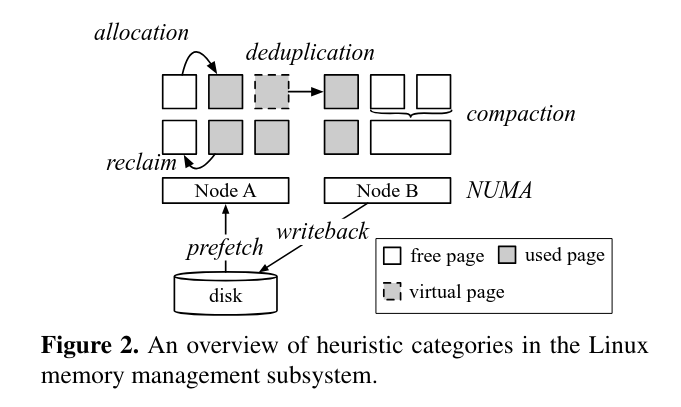
3.1 Overview of the heuristics
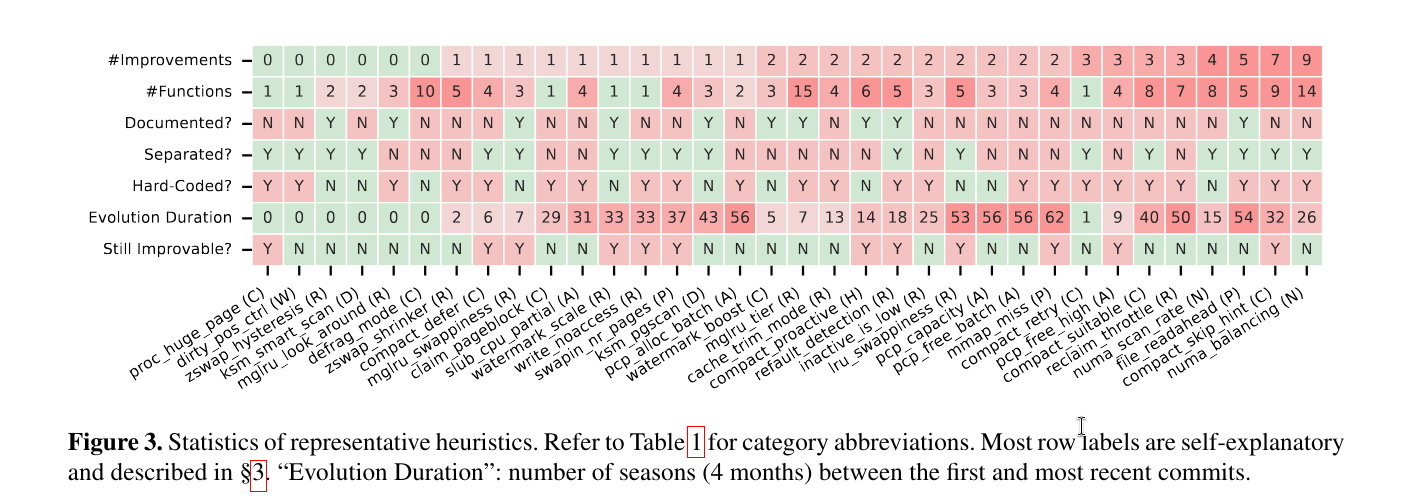
3.2 Pitfalls of Today’s Heuristics
Pitfalls
- 28/34 require at least one modification to reach satisfiable performance, and 18 are optimized more than once (\(\# Improvements\))
- 26 heuristics take more than 12 months from their initial introduction to reach their current form ($Evolution \space Duration$)
- 12 heuristics can be further optimized for certain workloads by changing the default setup
- 28 heuristics are implemented in more than one kernel functions (\(\# Functions\))
- 16 are not implemented as dedicated functions ($Separated?$)
- 23 do not provide any tunable parameter for mitigating anomalies ($Hardcoded?$)
- 24 are not documented in the kernel’s
Documentationdirectory or in header comments ($Documented?$)
4. Heuristic Anomaly
Heuristic anomalies arise for four major reasons:
- Conflicting utility objectives: users can value outcomes differently from the developers.
- Workload-dependent utility: some heuristics work well only under the workload patterns they are designed for.
- Hardware-dependent utility: heuristics implicitly assume specific hardware characteristics.
- Utility-cost trade-off: a low-cost algorithm limits the heuristic utility.

Conflicting utility objectives
Heuristic designers often face competing objectives: improving one metric can degrade another. Gives example of reclaim_throttle heuristics where delay increases and that creates memory constraints. The taken up memory can stall for long time before being killed because OOM is not triggered until reclaim has been tried a sufficient number of times.
Implication 1: Different environments may have different preferences on conflicting objectives. Heuristics should make such trade-offs tunable, or detect the current environment’s status for adaptive adjustment.
Workload-Dependent Utility
Even if a heuristic considers only a single objective, its quality can be highly workload-dependent. Gives example of 1) inactive_is_low and 2) cache_trim_mode.
inactive_is_low heuristic originally favored the stable case (small inactive list), but this caused severe performance regressions (thrashing) dur- ing workload transitions. The fix was to dynamically enlarge the inactive list when such thrashing (refaults) is detected.
cache_trim_mode heuristic avoids swapping when the inactive file list is large. However, this causes applications with large executable files to experience up to 3,000× higher memory access latency when cold anonymous pages occupy the memory. In this case, the cold anonymous pages should be swapped out instead of the file pages which may be accessed again.
Implication 2: Heuristics should consider involving automatic workload pattern detection, avoiding only optimizing for certain workload patterns based on optimistic or biased assumptions.
Hardware-Dependent Utility
Gives example of pcp_free_high and process_huge_page.
pcp_free_high drains the receiver’s per-CPU free-page cache after IPC frees so the sender can reallocate those pages and keep them cache-hot, but that draining can increase contention on the global pool. In their AF_UNIX IPC test it boosts throughput on Intel but can reduce it on AMD, because the cache-locality benefit is smaller with CCX/L3 sharing (and missing topology info makes it worse).
process_huge_page heuristic: on a huge-page fault, the kernel tries to handle the faulting sub-page last (to keep it cache-hot), and if the first sub-page faults it processes the huge page in reverse order; this helps a bit on Intel but regresses on AMD in their measurements. It can backfire because reversing sub-page order while still scanning cache lines sequentially confuses the hardware prefetcher and increases kernel-mode cache misses, and on AMD the per-CPU cache is large enough that the whole huge page often stays in cache anyway so the heuristic doesn’t reduce user-mode misses much.
Utility-Cost Trade-off
Low-cost heuristics are preferred, but simple heuristic algorithms may yield low-quality solutions and lead to heuristic anomalies.
slub cpu partial: To avoid cache-line contention, SLUB intentionally keeps an inaccurate free-object count for per-CPU partial slabs (it doesn’t update on every deallocation), which underestimates free objects and makes the allocator retain extra slabs—wasting memory (reported as 1.35 GB on a 56-core workstation).
Implication 4: Although low-cost heuristics may be inaccurate, developers rarely implement high-cost heuristics as the kernel is highly latency-critical.
5. Heuristic Maintainability
They summarize four key properties that, when missing, create a brittle environment for heuristic development:
- Diagnosability, without which developers cannot understand how a heuristic behaves, making diagnosis difficult.
- Testability, whose absence prevents building targeted tests or validating behavior across diverse scenarios.
- Extensibility, where poor support restricts the ability to refine heuristics as software or hardware changes.
- Cross-heuristic interactions awareness, without which developers cannot reason about how heuristics influence one another, often leading to unintended side effects.
1. Diagnosability
In Case #1, The readahead heuristic unexpectedly slows a random-read benchmark, and disabling it drops runtime from 6.2s to 1.5s. They eventually find the cause is a subtle bug: the per-file mmap_miss counter isn’t incremented for this workload, so readahead never gets turned off (and the logic is spread across multiple functions, making it painful to trace).
Implication 5: To ease diagnosis, heuristic code should be consolidated, with each component given a descriptive name that explains its design rationale.
They trace each code piece and see repeating execution patterns and mmap_miss values, but that alone doesn’t explain the bug. By also logging the faulting address and page-fault flags, they discover the retry after sync readahead incorrectly decrements mmap_miss, and they report the issue upstream.
Implication 6: Effective diagnosis requires contextual kernel information beyond the direct inputs and outputs of the heuristic procedure.
In Case 2, the compact_skip_hint heuristic (which skips pageblocks that recently failed compaction) drops thpcompact success from 96% to 65% because it often treats transient failures as if they were long-term and so makes wrong skip decisions. They traced the wrong skips to (1) transient migration failures (e.g., a sub-page stuck in the per-CPU pageset or on writeback) and (2) concurrent allocations that reallocate pages after migration, and they had to add extra tracepoints to confirm it.
Implication 7: Heuristic developers should document the limitations of the heuristic and provide tracepoints and guidance for anomaly diagnosis.
2. Testability
In Case #3, background compaction can start and then terminate immediately because the kernel uses two different fragmentation metrics: it starts based on a node-level weighted sum, but stops based on whether each zone’s weighted score falls below the same threshold. Since a high node-level sum doesn’t imply any single zone’s weighted score is high, this mismatch creates the awkward start-then-stop behavior and is hard to unit-test in today’s kernel because the termination logic is coupled with other code.
Implication 8: Implementation errors in heuristics are difficult to detect with general kernel testing. Thus, heuristics should be isolated to facilitate unit testing.
3. Extensibility
We need extensibility for kernel heuristics for adapting to different workloads, hardware, and system states, as well as to implement brand-new policies such as machine-learning based.
Case #4. Heuristics in Linux for swap-in perform well for some memory access patterns, but don’t for others. Recent works, such as FetchBPF and RMT allow developers to customize it, and they both have performed better than default heuristics.
Implication 9: Decoupling core algorithm of heuristics helps non-kernel experts design extensions and prevents extensions from increasing kernel complexity.
4. Cross-Heuristic Interactions Awareness
Multiple heuristics can interact and influence one another, through data-flow and control-flow dependencies.
Case #5: anomaly propagation due to a data-flow dependency. Enabling pcp capacity auto-tuning causes a 29% AF_UNIX IPC throughput drop, but the auto-tuning itself isn’t the real culprit. Auto-tuning sets high_min smaller, which makes pcp_free_high trigger more often (more lock contention), so the two heuristics’ shared variable forces developers to disable auto-tuning just to avoid an unrelated regression.
Case #6: misled analysis due to a control-flow dependency. Shrinking the compact_defer max timeout (from $2^6$ to $2^2$) raises thpcompact success from 65% to 89%, which can mislead you into thinking compact_defer was the real problem. But the actual root cause is compact_skip_hint: because skip hints get cleared when the defer hits its max timeout, a shorter timeout clears hints more often, indirectly improving compaction success.
Implication 10: Understanding (implicit) cross-heuristic interactions aids root-cause analysis of heuristic anomalies and helps prevent an anomaly in one heuristic from propagating to others
6. Towards a Kernel Heuristic Framework
6.1 Design Principles and High-Level Ideas
Kernel heuristics should be decoupled from the kernel mechanism and modularized behind a clean interface, with defined hook points that invoke heuristic hook functions when the kernel reaches them. They argue that grouping all code for a heuristic in one place improves maintainability and also makes it easier to trace behavior, generate documentation, write unit tests, and analyze cross-heuristic dependencies.
They propose a dual-layer interface where each heuristic callback is split into an outer layer (interacts with the kernel) and an inner “core” layer (the algorithm), with the outer layer calling the core via a dedicated function pointer. This separation keeps tuning safer (the core can stay stateless), makes it easy to extend what the heuristic “sees” by adding context in the outer layer, and gives a centralized place to add standard tracepoints for diagnosability.
Finally, the framework should allow multi-version core algorithms (policies) selectable via configuration. A “one size fits all” approach often fails, especially for heuristics designs, due to conflicting objectives.
6.2 Primitives for Heuristic Development