Man-Made Heuristics Are Dead. Long Live Code Generators!

HotNets, November 2025
We face rapid evolution in workloads, deployment settings, and heterogeneous hardware. As such, the design space of heuristics for most problems is complex and shifting in a context-dependent manner. Human developers often cannot discover “the right heuristics” fast enough. Meanwhile, learning-based systems have shown that it is possible to approach instance-optimality by finding the best policy for a given context by learning from data. However, neural approaches come at a steep cost: opaque behavior, complex training and deployment pipelines, inference overheads, and safety concerns that preclude adoption in many environments.
PolicySmith
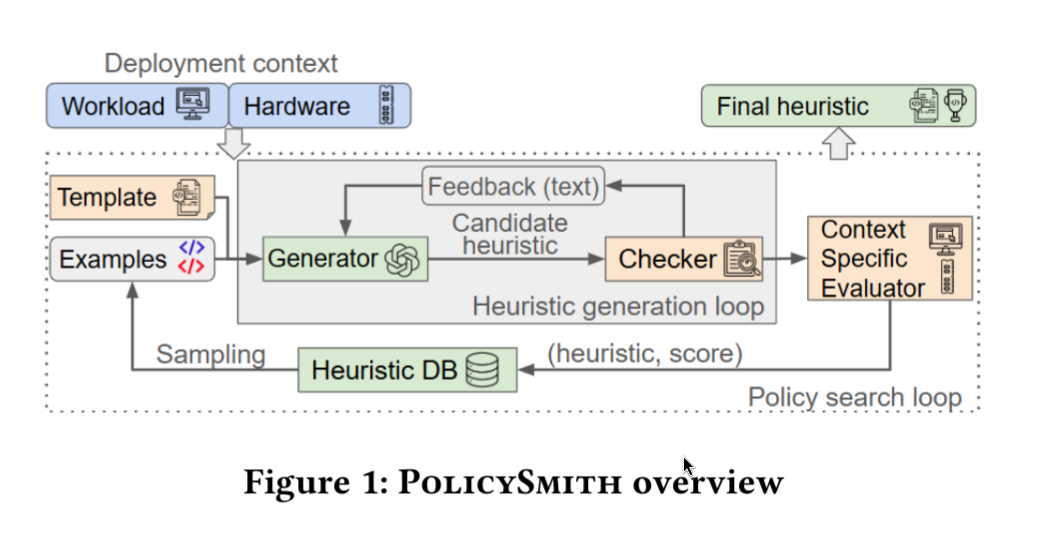
TEMPLATE must be provided by user, which contains function signature, or a partial code stub, as well as natural language constraints, such as which libraries may be imported, the states it can access, and any behavioral or performance requirements. Then LLM would generate candidate heuristic functions. But of course, LLM can hallucinate, therefore, a user-defined CHECKER is necessary that enforces syntactic and semantic rules, and provides structured feedback to help generators stay within spec.
Once a candidate passes the CHECKER’s check, it gets evaluated by EVALUATOR and assigned a score, and the best-performing candidates are fed back as examples in the next round. This loop continues for several iterations, gradually steering the generator toward better-performing heuristic code. At the end, POLICYSMITH outputs a final heuristic tailored to the target context.
Case Study: Web Caching
In the web-caching case study, the paper applies PolicySmith to automatically synthesize cache eviction heuristics and evaluates them inside libCacheSim, treating a “context” as a specific (trace, cache size) pair and optimizing miss rate at a cache size set to 10% of the trace footprint. To keep synthesis reliable while still expressive, they fix the implementation to a template where cached objects are managed in a priority queue, and the LLM generates only a single function, priority(), which updates an object’s score on access/insertion and evicts the lowest-score item; priority() can use per-object signals (e.g., recency/frequency/size), aggregate statistics, and a short history of recent evictions. They note this design may add O(log N) update overhead per access (because of the priority queue), and suggest approximate structures if that cost is too high in practice.
The search is seeded with simple policies like LRU/LFU and run as an iterative generate-and-test loop (20 rounds, 25 candidates per round, feeding back the top performers), repeated per trace to produce multiple heuristics. On their target traces, the synthesized heuristic for that context matches or beats a suite of 14 baseline eviction policies, and some heuristics retain strong performance across other traces in the same dataset (e.g., Heuristic A wins on 48% of CloudPhysics traces; Heuristic X on 64% of MSR traces), indicating partial within-dataset transfer rather than purely trace-specific tuning. They also report the optimization is inexpensive in practice, with a full search run taking only a few CPU-hours and low single-digit dollars of API cost across their runs.
Case Study: Congestion Control
In this case study, they focused on being able to implement a working heuristic code in a largely strict and constrained environment instead of chasing more optimal heuristic.
Only cong_control, the decision function for TCP congestion control in Linux kernel, is exposed to GENERATOR.
TEMPLATE is implemented as a Linux kernel module, and it provides history arrays – time series arrays that capture smoothed versions of these metrics over the last 10 RTT intervals.
An eBPF probe is attached to cong_control. Whenever the function is run, the LLM-generated BPF program also executes. The BPF verifier acts as CHECKER. The eBPF program executes the generated logic, computes the updated decision, and writes the result to a BPF map.
They generated 100 candidate congestion control heuristics and attempted to compile them into eBPF programs. Only 63% of the candidates passed the eBPF verifier on the first try, and an additional 19% successfully compiled after the GENERATOR was provided with the stderr. The most common causes of errors were the use of floating-point arithmetic and missing checks for division by zero.