Towards Agentic OS: An LLM Agent Framework for Linux Schedulers

MLforsystem workshop'25
The paper presents SchedCP, a control-plane framework that lets autonomous LLM agents safely optimize Linux scheduling by separating semantic reasoning (“what to optimize”) from system execution (“how to observe and act”). It pairs this with sched-agent, a multi-agent system that analyzes workloads and generates/deploys sched_ext eBPF schedulers, reporting up to 1.79× performance improvement and 13× cost reduction versus naive agentic approaches.
1 Introduction
Linux’s general-purpose scheduler policies (e.g., EEVDF) can’t directly infer what an application actually needs, causing a “semantic gap,” even though sched_ext makes safe custom schedulers possible via eBPF.
Prior RL-based approaches typically lack workload semantics and often only tune within a human-specified search space, while naive LLM coding is reported as slow/expensive and sometimes performance-regressing.
Their core move is to split autonomous optimization into goal-inference (extract goals/constraints from workload) and policy-synthesis (compile into an eBPF scheduler policy).
2 Motivation
They identify three blockers to practical scheduler optimization: (1) a knowledge gap between operators/users and kernel scheduling behavior, (2) the expertise barrier of kernel development, and (3) dynamic workload behavior (traffic and parallelism shift over time).
LLMs can help via tool-assisted workload exploration, semantic reasoning about code/workloads, and synthesizing eBPF schedulers while keeping heavy inference out of the scheduler hot path by operating from the control plane.
A “naive agent” experiment suggests direct LLM coding can be slow/expensive and sometimes unsafe/ineffective.
3 The SchedCP Framework Design and Implementation
SchedCP is a secure, decoupled control plane for OS optimization: AI decides what to optimize, while SchedCP controls how to observe/act via stable tools and defensive interfaces.
Design principles: decoupling/role separation, safety-first interfaces (treat agents as non-cautious; avoid root), adaptive context provisioning (progressive detail to manage token/context costs), and composable atomic tools (Unix-y building blocks).
Core services:
Workload Analysis Engine: Provides tiered access to system performance data: (1) cost-effective API endpoints with pre-processed summaries (CPU load, memory usage), (2) secure sandbox access to file reading, application building, Linux profiling tools (perf, top) and dynamically attachable eBPF probes, (3) feedback channel reporting post-deployment metrics (percentage change in throughput/latency).
Scheduler Policy Repository: Database storing executable eBPF scheduler programs with metadata (natural language descriptions, target workloads, historical performance metrics). It provides APIs for semantic search and retrieval, enabling agents to find relevant schedulers or composable code primitives. To support system evolution, it includes endpoints for updating performance metrics and promoting new policies, reducing generation costs by allowing reuse of proven solutions while maintaining a growing library of scheduling strategies.
Execution Verifier: includes a multi-stage validation pipeline: (1) kernel’s eBPF verifier ensures memory safety and termination, (2) scheduler-specific static analysis detects logic flaws (starvation, unfairness) the standard verifier misses, (3) dynamic validation in secure micro-VM tests correctness and performance. Successful validation issues signed deployment tokens for monitored canary deployments with circuit breakers to revert if performance degrades, eliminating sched-agent’s need for root access.
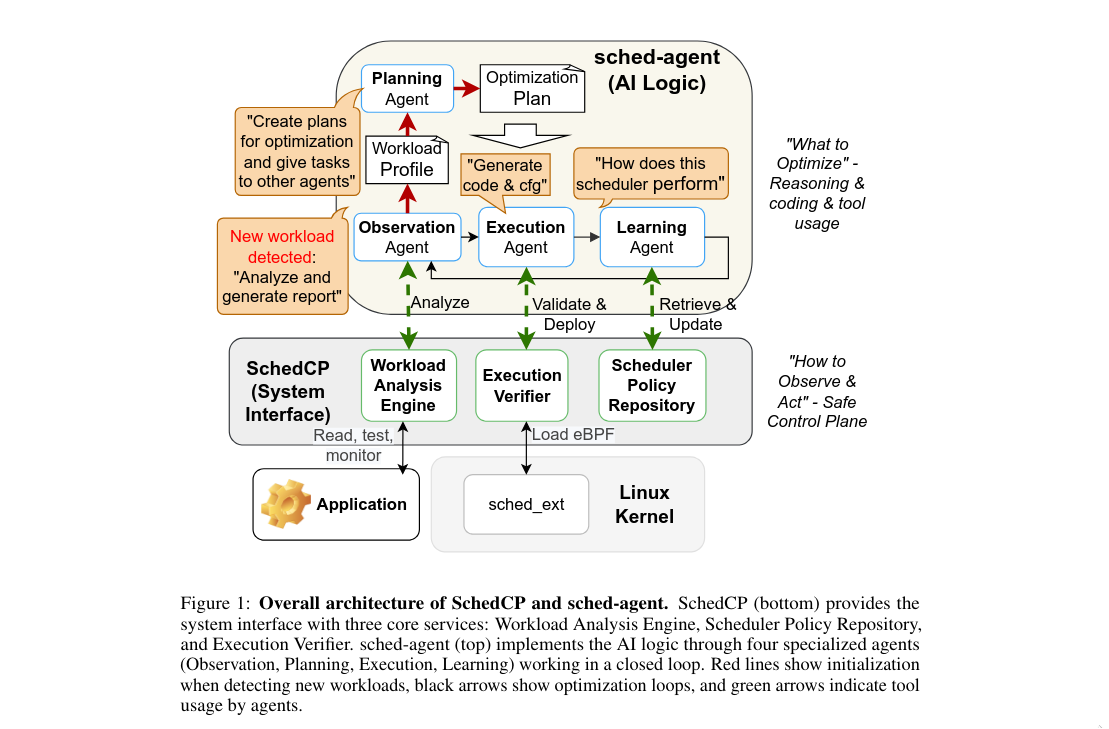
4 sched-agent: A Multi-Agent Framework for OS Optimization
On top of SchedCP, sched-agent decomposes the loop into four specialized agents: Observation, Planning, Execution, and Learning, using separate contexts and tools to iteratively improve a scheduler without retraining. The** Observation Agent** builds Workload Profiles by querying the Workload Analysis Engine strategically, starting with high-level summaries from process name and commands then requesting deeper profiling (perf stat, top) based on findings, synthesizing data into natural language descriptions and optimization goals while managing cost-precision tradeoffs. For kernel compilation, it produces profiles like “CPU-intensive parallel compilation with short-lived processes, inter-process dependencies, targeting makespan minimization.” The Planning Agent transforms profiles into optimization strategies via the Scheduler Policy Repository, following a decision hierarchy: configuring existing schedulers, generating patches, or composing new schedulers from primitives. The Execution Agent manages development, validation and deployment by synthesizing code artifacts, submitting to the Execution Verifier, interpreting results to refine code or fix logic issues. The Learning Agent completes the ICRL loop by analyzing deployment outcomes (e.g., 45% makespan reduction), enabling in-session adaptation and updating the repository with refined metrics, deployment contexts, and documented antipatterns.
5 Preliminary Evaluation
They evaluate across multiple scenarios, testing whether agents can configure existing schedulers, synthesize new ones, reduce cost, and improve via iteration.
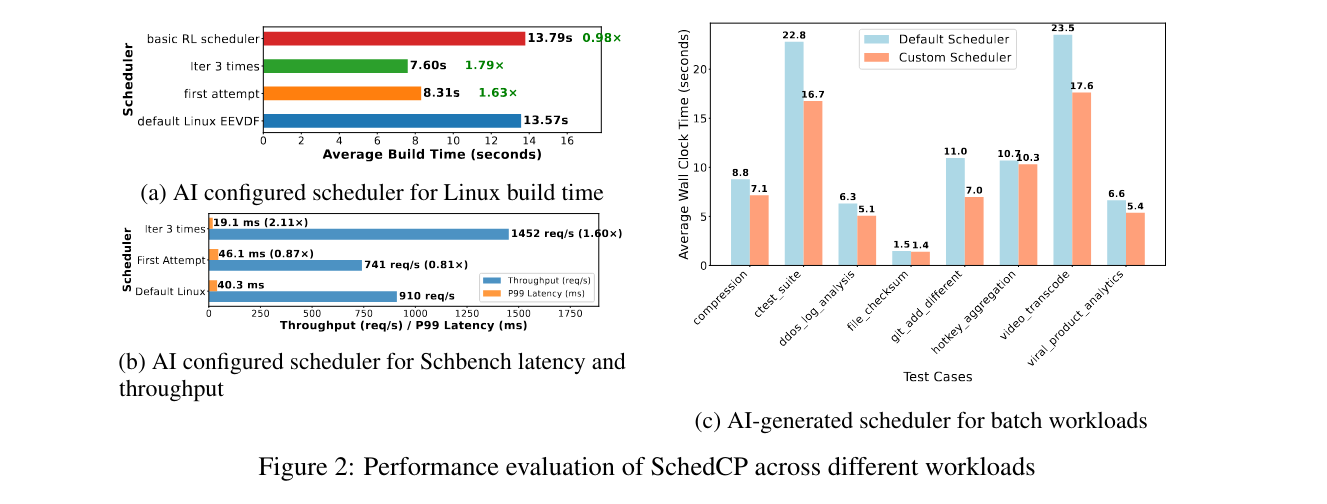
Reported results include: kernel compilation speedups up to 1.79× vs EEVDF after iterative refinement, and on schbench improvements of 2.11× P99 latency and 1.60× throughput after refinement.
For long-tail batch workloads, sched-agent identifies the pattern and implements Longest Job First, yielding ~20% average latency reduction, and reports large efficiency gains in generation time/cost.
6 Missing Implementation
- Workload Analysis Engine (Sect. 4.2.1, document/2509.01245v2.txt): The paper calls for a tiered interface that gives agents (1) cost‑effective summaries, (2) a sandbox for profiling tools (perf, top, strace, attachable eBPF probes) and (3) a feedback channel with post‑deployment metrics. In the repo the only monitoring support is mcp/src/system_monitor.rs, which merely samples /proc/stat, /proc/meminfo and /proc/schedstat once per second and exposes start/stop summaries—there is no sandboxed profiling environment, no on‑demand perf/probe tooling, no event subscription mechanism, and no structured feedback channel. The document/devlog.md checklist even explicitly marks the Workload Analysis Engine as “not implemented.”
- Scheduler Policy Repository (Sect. 4.2.2): The paper envisions a vector database that stores eBPF code + rich metadata, exposes semantic search, and tracks historical performance so agents can reuse, patch, or promote policies. The current implementation only reads a static scheduler/scx/schedulers.json and loads binaries from ~/.schedcp/scxbin via mcp/src/scheduler_manager.rs; there is no database of new policies, no embedding/semantic search, no metadata updates, and no API to persist custom scheduler code or performance metrics. The devlog improvement plan also calls out the lack of a repository.
- Execution Verifier (Sect. 4.2.3): The paper describes a multi‑stage validation pipeline (static analysis, micro‑VM sandboxed tests, deployment tokens, canary rollouts, circuit breakers and rollback). In this codebase the closest thing is SchedulerGenerator::verify_scheduler/execution_verify (mcp/src/scheduler_generator.rs lines ~140‑620), which simply loads the compiled BPF program into the kernel, runs it for 10 s, and checks stderr for errors. There is no static verifier beyond the usual kernel verifier, no multi‑stage sandbox, no signed deployment token, no circuit breaker/canary rollback logic, and no structured failure reporting.
- sched-agent multi‑agent loop (Sect. 5, document/sched-agent-design.md): The paper’s “Observation → Planning → Execution → Learning” agents are meant to exchange structured data, run specialized tools, and iterate via in‑context reinforcement learning, reacting to Kubernetes/daemon triggers. The repo only has the single autotune CLI (autotune/src/) and the MCP server; there is no implementation of the four agents, no agent coordination, and no automation hooks (Kubernetes/Docker wake‑ups) that the paper describes. The design docs and devlog also list these agents as future work, so that portion remains unimplemented.