TMO: Transparent Memory Offloading in Datacenters
1. Introduction
The paper argues that DRAM has become too expensive as a stand-alone capacity solution because application memory demand (e.g., ML) is rising while DRAM scaling slows and costs fluctuate. It notes that datacenters now commonly have cheaper “slow” tiers (NVMe SSDs, NVM, and emerging CXL-style memory buses), creating an opportunity for memory tiering—migrating colder data to slower, cheaper media.
The authors focus on kernel-driven swapping because it can be applied transparently, and they highlight Google’s production zswap-based approach (“g-swap”) as the main large-scale precedent—but point out two key limits: it only uses one slow tier (compressed memory) and it depends on offline profiling plus a static “promotion rate” (number of swap-ins per second) target that doesn’t reliably reflect app sensitivity or device performance.
To overcome this, they introduce TMO: it answers “how much to offload” using Pressure Stall Information (PSI), which directly measures lost work from CPU/memory/I/O shortage, and a userspace controller (Senpai) that uses PSI feedback to adapt offloading across heterogeneous backends without prior app knowledge. For “what to offload,” they describe kernel changes to more evenly balance offloading between file cache and anonymous memory (instead of heavily favoring file cache, like how it’s traditionally done by kernel), and they emphasize targeting not just app containers but also “sidecar”/infrastructure containers and respecting container hierarchies/priorities.
2. Memory Offloading Opportunities and Challenges in Datacenters
Memory and SSD Cost Trends
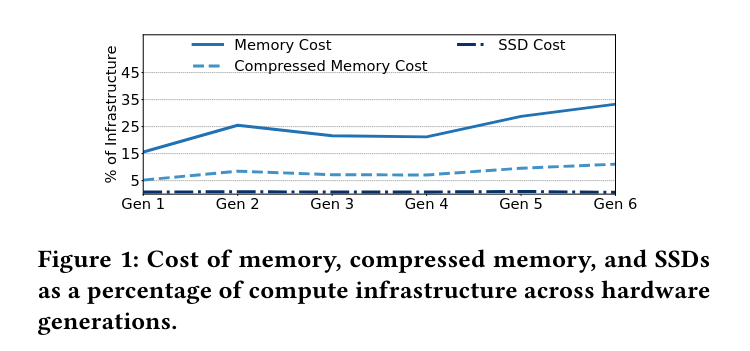
The cost of DRAM is expected to grow and reach 33%, while, even though not shown in the figure, the DRAM power consumption will reach 38%. Therefore, we need alternative memory technologies such as NVMe SSDs to further drive down the cost more aggressively.
Cold Memory vs Offloading Opportunity

The memory offloading opportunity (i.e., fraction of cold memory) averages about 35%, but varies wildly across applications in a range of 19-62%, which emphasizes the importance of having an offloading method that is robust against application’s diverse memory behaviors.
Memory Tax
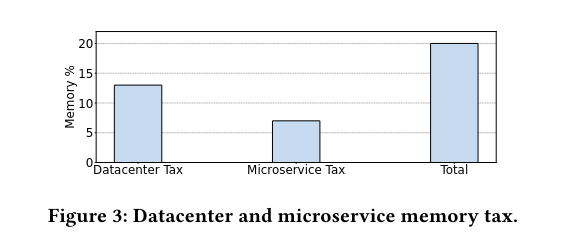
Datacenter memory tax – the memory required for software packages, profiling, logging, and other supporting functions related to the deployment of applications in datacenters.
Microservice memory tax – all the memory required by applications due to their disaggregation into microservices, e.g., to support routing and proxy, and it is applicable uniquely to microservice architectures.
Anonymous and File-Backed Memory

Anonymous memory is allocated by applications and is not backed by a file or a device. File-backed memory represents allocated memory in relation to a file and is further stored in the kernel’s page cache.
Figure 4 shows the breakdown of anonymous and file-backed memory for several large applications, datacenter memory tax, and microservice memory tax.
Hardware Heterogeneity of Offload Backend
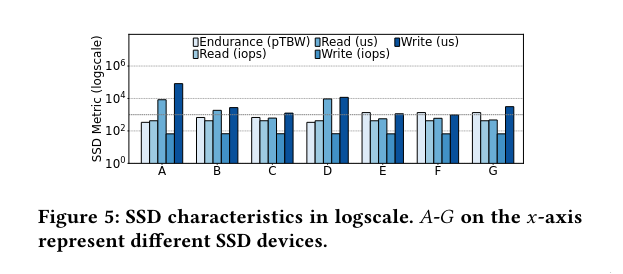
Newer devices are to the right. Overall, a memory offloading system needs to effectively tackle a heterogeneous fleet despite large differences in offload backends.
3. TMO Design
Fundamentally, TMO addresses the questions of how much memory to offload and what memory to offload.
Transparent Memory Offloading Architecture
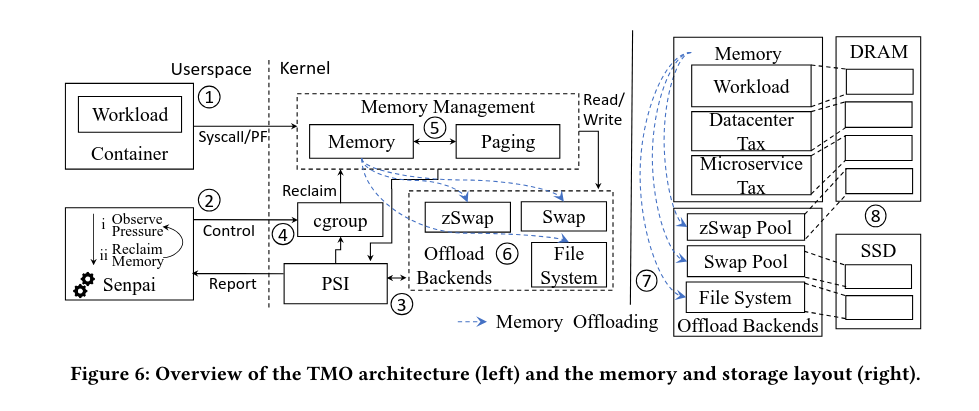
PSI Metrics
In determining how much memory to offload, we need a measure of the impact on application performance due to lack of memory. To track memory pressure, PSI calculates the percentage of stalls exclusively due to shortage of memory with some and full variables in percentages. The some metric tracks the percentage of time in which at least one process within the domain is stalled waiting for the resource. The full metric tracks the percentage of time in which all processes are delayed simultaneously.
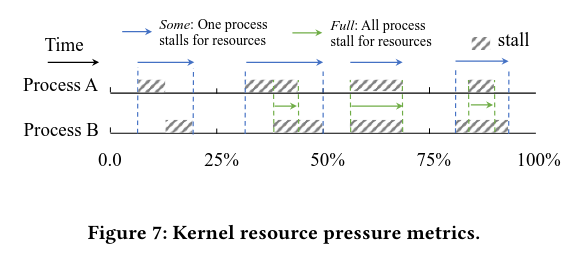
In figure 7, for the first quarter, some is 12.5%. For the second quarter, some is 18.75% and full is 6.25%.